Los clústeres virtuales son clústeres de Kubernetes en pleno funcionamiento que se ejecutan sobre otros clústeres de Kubernetes. En comparación con los clústeres “reales” completamente separados, los clústeres virtuales no tienen sus propios grupos de nodos. En cambio, están programan cargas de trabajo dentro del clúster subyacente mientras tienen su propio plano de control separado.

El clúster virtual en sí solo consta de los componentes centrales de Kubernetes: servidor API, Controller Manager y base de datos (como etcd, sqlite, mysql, etc.). Para reducir la sobrecarga del clúster virtual, vcluster se basa en k3s , que es una distribución de Kubernetes liviana, certificada y totalmente funcional que compila los componentes de Kubernetes en un solo binario y deshabilita todas las funciones de Kubernetes que no son necesarias, como el scheduler o ciertos controladores.
Además de k3s, hay un hipervisor de Kubernetes que reemplaza al programador de Kubernetes y emula una configuración de Kubernetes completamente funcional en el clúster virtual. Este componente sincroniza un conjunto de recursos básicos que son esenciales para la funcionalidad del clúster entre el clúster virtual y el host:
- Pods : todos los pods que se inician en el clúster virtual se reescriben y luego se inician en el espacio de nombres del clúster virtual en el clúster de host. Los tokens de la cuenta de servicio, las variables de entorno, el DNS y otras configuraciones se intercambian para apuntar al clúster virtual en lugar del clúster de host. Dentro del pod, parece que el pod se inicia dentro del clúster virtual en lugar del clúster de host.
- Services : todos los servicios y puntos finales se reescriben y crean en el espacio de nombres del clúster virtual en el clúster de host. El clúster virtual y de host comparten las mismas direcciones IP del clúster de servicios. Esto también significa que se puede acceder a un servicio en el clúster de host desde dentro del clúster virtual sin ninguna penalización de rendimiento.
- PersistentVolumeClaims : si se crean notificaciones de volumen persistentes en el clúster virtual, se modificarán y crearán en el espacio de nombres del clúster virtual en el clúster de host. Si están vinculados en el clúster de host, la información del volumen persistente correspondiente se sincronizará con el clúster virtual.
- ConfigMaps y Secrets : Los configmaps o secrets en el clúster virtual que se montan en los pods se sincronizarán con el clúster de host, todos los demás mapas de configuración o secretos permanecerán puramente en el clúster virtual.
- Otros recursos : los deployments, los statefulsets, los CRD, las service account, etc. NO están sincronizados con el clúster de host y existen únicamente en el clúster virtual.
Los clústeres virtuales resuelven muchos de los problemas que presentan los namespaces, como:
Recursos con ámbito de clúster : determinados recursos viven globalmente en el clúster y no puede aislarlos mediante espacios de nombres. Por ejemplo, no es posible instalar istio o cualquier otro operador en diferentes versiones dentro de un solo clúster.
Plano de control de Kubernetes compartido : el servidor de API, etcd, el scheduler y el controller-manager se comparten en un solo clúster de Kubernetes. La limitación de la velocidad de solicitud o almacenamiento basada en un espacio de nombres es muy difícil y una configuración defectuosa puede hacer que se caiga todo el clúster.
Los clústeres virtuales también proporcionan más estabilidad que los namespaces en muchas situaciones. El clúster virtual crea sus propios objetos de recursos de Kubernetes, que se almacenan en su propio almacén de datos. El clúster de host no tiene conocimiento de estos recursos.
Debido a que puede tener muchos clústeres virtuales dentro de un solo clúster, son mucho más baratos que los clústeres tradicionales de Kubernetes y requieren menos esfuerzos de administración y mantenimiento. Esto los hace ideales para la ejecución de experimentos, la integración continua y la configuración de entornos de espacio aislado.
Por último, los clústeres virtuales se pueden configurar independientemente del clúster físico. Esto es excelente para múltiples usuarios.
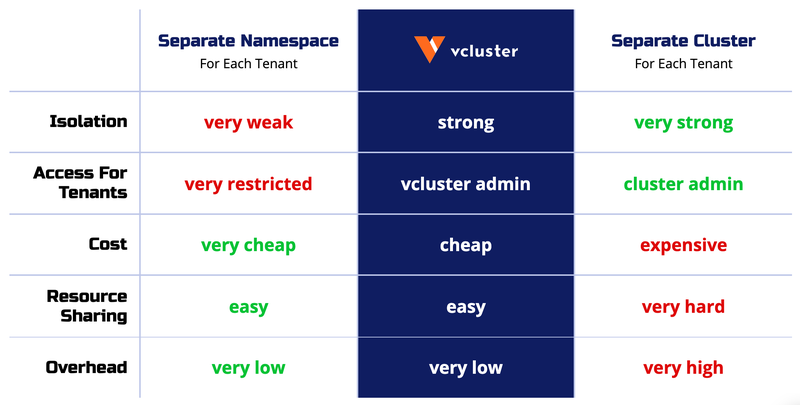
En la siguiente imagen se muestra una comparación entre los namespaces, los vcluster y los clusters independientes